

AI Algorithms to improve the use of chaos engineering
AI can improve the efficiency and effectiveness of chaos engineering. AI algorithms help identify potential false positives
Read moreAutomation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.
Complex infrastructures, diverse technologies, and an ever-expanding number of interconnected components make it difficult to anticipate and prevent failures. Issues like server outages, network disruptions, and unplanned traffic spikes can cripple operations, affecting everything from customer experience to revenue generation. Moreover, as systems grow in complexity, traditional methods of testing and monitoring often fall short in predicting how a system will behave under real-world stress.
This is where Chaos Engineering comes into play. Chaos Engineering is a proactive approach that involves deliberately introducing disruptions or failures into a system to observe its behavior under stress. By simulating real-world incidents, teams can identify vulnerabilities and potential points of failure before they affect actual users or customers.
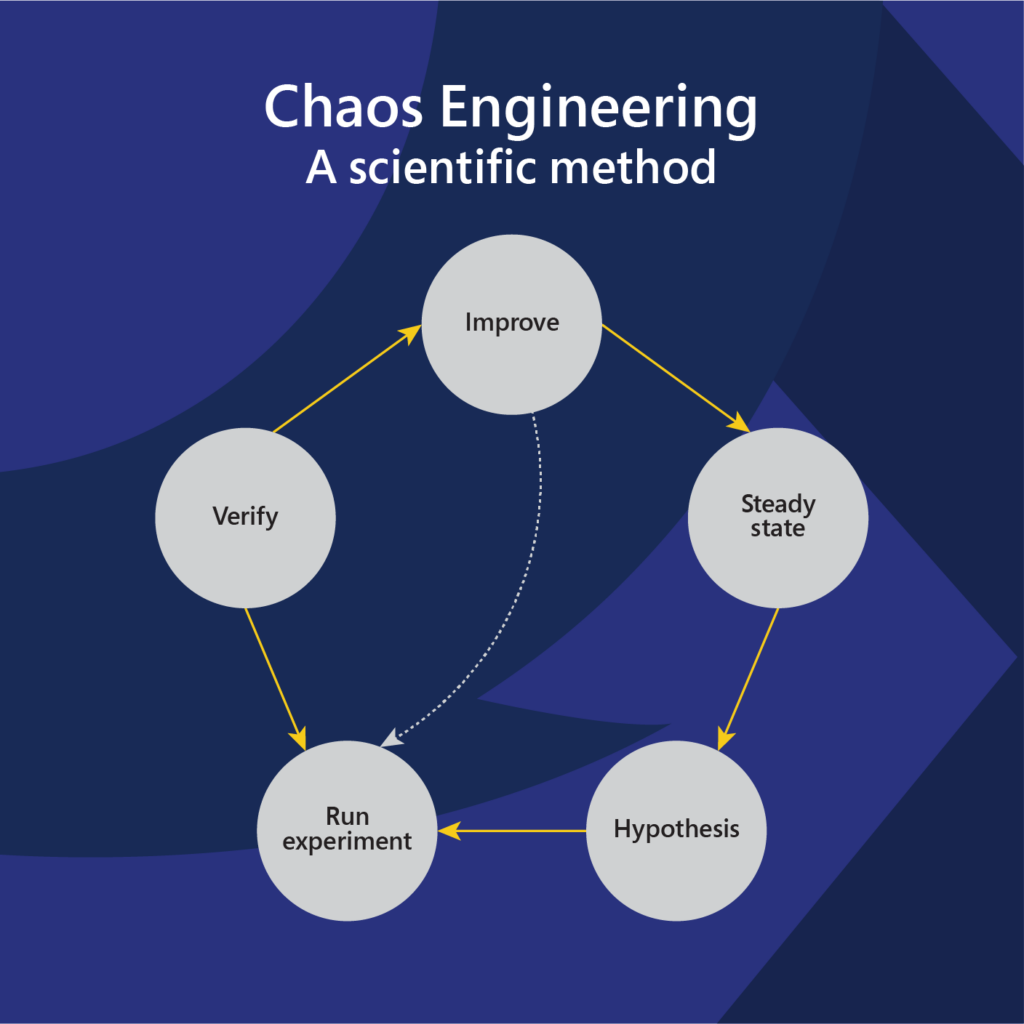
According to a study by Gartner, the average cost of IT downtime is $5,600 per minute. Businesses cannot afford to leave system resilience to chance. Your business needs an AI-powered chaos engineering platform to proactively ensure system resilience in an increasingly complex and interconnected digital landscape. Traditional methods struggle to keep up with the scale and sophistication of modern systems, but AI-driven platforms automate experiment design, predict vulnerabilities, and simulate thousands of failure scenarios. This enables organizations:

In a world where uptime equals credibility, by leveraging AI, your business can confidently innovate, maintain seamless operations, and safeguard customer trust even under stress.
While chaos engineering has proven effective in strengthening systems, traditional approaches come with challenges that can limit their scalability and efficiency. Some of the most common obstacles include:
Executing chaos experiments often requires significant manual effort, including designing experiments, monitoring system responses, and implementing fixes. This can place a strain on resources, particularly in organizations with limited engineering teams.
Executing chaos experiments often requires significant manual effort, including designing experiments, monitoring system responses, and implementing fixes. This can place a strain on resources, particularly in organizations with limited engineering teams.
Traditional chaos engineering is typically reactive, testing systems based on present vulnerabilities without predicting future risks. This leaves organizations exposed to evolving threats.

Conducting too many disruptions in a short time can destabilize systems and negatively affect user experiences. Finding the right balance between testing and maintaining system stability is essential to avoid unintended outages.
It can be challenging to quantify the impact of chaos engineering on system resilience and business outcomes. Without clear metrics, organizations may struggle to justify the investment, especially in resource-constrained environments.
AI is revolutionizing chaos engineering by addressing its traditional limitations. With machine learning and predictive analytics, AI can help businesses run more targeted, scalable, and efficient chaos experiments. Here’s how AI addresses these pitfalls:
AI algorithms can analyze historical system data and design chaos experiments tailored to the system’s most vulnerable areas. This reduces the manual effort involved in creating experiments and increases their precision.
For example, Google’s SRE team uses AI to optimize their chaos experiments, targeting the highest-risk areas and increasing the efficiency of testing.
Machine learning can simulate thousands of failure scenarios simultaneously, making it easier to conduct comprehensive testing without overloading resources. This allows organizations to scale their testing efforts and ensure they are prepared for a wider range of potential failures.
By identifying patterns in historical data, AI can predict future vulnerabilities and potential system failures. This proactive approach shifts chaos engineering from a reactive to a preventive strategy, allowing organizations to address risks before they manifest in production environments.
AI models can assess the potential impact of proposed chaos experiments on production systems. This allows teams to fine-tune the level of disruption, reducing the likelihood of unintended consequences and minimizing the risk to business operations.
Advanced analytics provide actionable insights that can quantify improvements in system resilience, offering clear metrics to measure the ROI of chaos engineering initiatives. This makes it easier for organizations to track the value of their investment and justify future resources allocated toward chaos engineering efforts.
Qinfinite, our intelligent application management platform, integrates AI-powered chaos engineering to help businesses create resilient systems by injecting controlled chaos into them. The goal is to find weaknesses in the system before they become major issues and to build systems that can withstand failures.
Here’s how Qinfinite gives your business an edge:
In an era where systems form the backbone of businesses, resilience is non-negotiable. By combining the principles of chaos engineering with the power of AI, organizations can transition from merely surviving disruptions to thriving through them. Imagine a world where downtime is a thing of the past, customer satisfaction becomes a guarantee, and your teams are free to focus on the next big leap forward.
With Qinfinite, that vision is not just a possibility; it’s your competitive reality. With its AI-powered chaos engineering capabilities, Qinfinite makes it possible to embrace controlled chaos, ensuring your systems are ready for anything—and your business remains unstoppable.
Implementing chaos engineering promotes a culture of continuous improvement. Teams become accustomed to testing their systems, leading to increased collaboration and knowledge sharing. This culture shift encourages innovation and can drive better performance across the organization.
When businesses prioritize resilience, they significantly reduce the risk of outages that negatively affect user experiences. A study from Google Cloud found that companies that implement chaos engineering report higher customer satisfaction and retention rates, directly impacting their revenue and brand loyalty.
In an era where downtime can lead to severe financial repercussions and lost customer trust, adopting Chaos Engineering practices is not just a luxury but a necessity. By identifying vulnerabilities, improving system resilience, fostering a culture of experimentation, and enhancing user experiences, businesses can proactively combat the threats posed by unplanned downtime. As organizations continue to navigate the complexities of modern digital environments, leveraging chaos engineering will become increasingly vital in ensuring consistent performance and customer satisfaction.
At Quinnox, we understand the high stakes of unplanned downtime and the critical role resilience plays in driving customer satisfaction and operational excellence. Our advanced digital solutions leverage Chaos Engineering principles, allowing us to identify vulnerabilities early, optimize system resilience, and maintain seamless user experiences.
Ready to turn Chaos Engineering into a core component of your digital transformation journey, ensuring not only stability but also a foundation for continuous innovation and growth?
Connect with our Experts Today!
Why It Matters:

Best Practices:
Capacity metrics determine whether your infrastructure can meet current and future resource demands. These metrics assess the availability of compute, storage, and network resources against anticipated workload volumes.
Why It Matters:
Without adequate capacity planning, businesses face unexpected outages, which can disrupt operations and damage customer trust. Capacity metrics help forecast resource requirements, ensuring smooth scaling during growth or peak demand periods.
Best Practices:
Utilization metrics track the percentage of available resources (CPU, memory, disk, and network) being consumed to handle workloads. They provide insight into whether resources are being underused, overutilized, or balanced effectively.
Why It Matters:
Underutilization leads to wasted resources and increased costs, while overutilization risks system crashes and degraded performance. Striking the right balance optimizes costs and ensures reliable operations.

Best Practices:
Health metrics evaluate the overall condition of your infrastructure, including server uptime, error rates, and hardware failures. These metrics provide an early warning system for potential issues, enabling pre-emptive action.
Why It Matters:
Unhealthy infrastructure leads to frequent outages, degraded performance, and increased operational costs. Monitoring health metrics ensures that systems remain operational and reliable.
Best Practices:
Monitoring these four key metrics—Performance, Utilization, Capacity, and Health—offers significant business benefits across industries:

The real value of these metrics lies in how you use them to drive actionable insights. Here’s a step-by-step approach to integrating these metrics into your IT monitoring strategy:


Effective IT infrastructure monitoring is a cornerstone of modern business success. Monitoring performance, utilization, capacity, and health metrics provides a robust foundation for IT infrastructure management. However, managing these metrics in isolation can be overwhelming.
This is where Quinnox’s intelligent application management (iAM) platform, Qinfinite, comes into play. With its advanced capabilities in data integration, real-time analytics, and AI-powered insights, Qinfinite empowers businesses to excel across all four metrics. From pinpointing latency issues to optimizing resource utilization, scaling capacity, and ensuring infrastructure health, Qinfinite delivers unparalleled visibility and control.
Ready to redefine your IT operations? Why Wait? Request for a 120 – Minutes Free consultation and discover how Qinfinite can empower your infrastructure today!
Traditional chaos engineering relies on manual experiment design and reactive testing, whereasAI-powered chaos engineering uses machine learning and predictive analytics to designexperiments, predict future risks, and scale testing efforts. AI also minimizes the risk ofdisruption and provides data-driven insights for measuring ROI.
Traditional chaos engineering relies on manual experiment design and reactive testing, whereasAI-powered chaos engineering uses machine learning and predictive analytics to designexperiments, predict future risks, and scale testing efforts. AI also minimizes the risk ofdisruption and provides data-driven insights for measuring ROI.
The future of AI-powered chaos engineering looks promising. As AI technology advances, we can anticipate more sophisticated platforms that automate the chaos engineering process, making implementation easier for organizations. These platforms will likely expand their support to a wider range of systems and applications.
While generally applicable, the specific implementation may vary depending on the system’s complexity, criticality, and the organization’s risk tolerance. Highly critical systems may require more cautious and controlled experiments.
AI-powered platforms can be designed with built-in safeguards and ethical considerations. These may include mechanisms to prioritize safety, minimize user impact, and ensure compliance with relevant regulations.
Yes, by identifying bottlenecks and performance limitations during controlled chaos experiments, organizations can gain insights into system performance and optimize resource allocation for improved efficiency.
By proactively identifying and mitigating vulnerabilities, Qinfinite empowers your organization to deliver highly reliable and resilient systems. This translates to increased customer satisfaction, reduced downtime, and a stronger competitive edge in today’s demanding digital landscape.
AI can improve the efficiency and effectiveness of chaos engineering. AI algorithms help identify potential false positives
Read moreIdentify system vulnerabilities and enhance resilience to improve customer experience using best practices in chaos engineering. Read the Gartner report!
Read moreOur client is the largest independent mail, courier and logistics operator in the UK and Ireland
Read moreGet in touch with Quinnox Inc to understand how we can accelerate success for you.