
It’s the start of the Black Friday Month, and your e-commerce platform is gearing up for a record-breaking sales surge. Suddenly, a technical glitch causes the site to crash, leaving thousands of eager customers frustrated and empty-handed. According to Gartner, unplanned downtime can cost companies an average of $5,600 per minute, translating into not just lost revenue but a potential loss of customer loyalty that can take months, if not years, to rebuild.
This is where Chaos Engineering comes into play— a revolutionary approach that flips the script on traditional testing methods. Rather than waiting for failures to occur in real time, chaos engineering advocates for the intentional introduction of faults into systems to observe how they respond under pressure. This proactive methodology not only uncovers hidden vulnerabilities but also equips businesses with the insights needed to fortify their infrastructure against unexpected disruptions.
Understanding Chaos Engineering
Chaos Engineering is the practice of intentionally introducing faults into a system to test its resilience. By simulating failures, such as server crashes, network outages, or service interruptions, organizations can observe how their systems behave under stress. The goal is not to break the system but to understand how it can be improved.
QA involves activities built around a framework to implement standards and procedures, focusing on the processes that can potentially lead to the best outcomes rather than the actual testing of products. This process-driven approach significantly helps organizations maintain consistent quality throughout the software development lifecycle.
Why Do You Need Chaos Engineering?
1. Rising Complexity of Systems: As organizations adopt microservices architectures, their systems become increasingly complex. Each service communicates with others, making it difficult to predict how failures in one component can affect the entire system. For example, A company has reported that they run over 1,000 chaos experiments daily to ensure their services remain resilient despite system complexity.
2. User Expectations: With the advent of digital transformation, user expectations have skyrocketed. A survey from PwC found that 32% of customers would stop doing business with a brand they love after just one bad experience. This underscores the need for businesses to maintain high availability and performance to meet customer demands.
3. Increasing Dependency on Digital Services: As more businesses transition to digital-first strategies, any downtime can lead to significant revenue losses. According to the research, for organizations in high-risk industries, such as finance, the cost of downtime can exceed $5 million per hour. Globally, businesses lose $250 million per year due to downtime.
Read the complimentary Gartner report: Market Guide for Chaos Engineering Tools
Read the complimentary Gartner report: Market Guide for Chaos Engineering Tools
Navigating the Maze of Challenges in Preventing Unplanned Downtime
Once you’ve made the leap to automated regression testing, the next step is to ensure that your tests are truly effective. How do you quantify success? Let’s explore the most important metrics you should track.
Despite the benefits, many organizations face hurdles in preventing unplanned downtime:
1. Legacy Systems: Many companies still rely on outdated technology that may not support modern practices like chaos engineering. Legacy systems can introduce vulnerabilities that are difficult to detect and resolve.
2. Lack of Testing Culture: Organizations that prioritize rapid deployment over rigorous testing often overlook potential weaknesses. Without a culture that values testing and experimentation, teams may struggle to identify issues before they escalate.
3. Inadequate Monitoring: Insufficient monitoring tools can lead to a lack of visibility into system performance. Without proper monitoring, it’s challenging to identify anomalies and potential failures, resulting in prolonged outages.
Staying Competitive in the Market

How Chaos Engineering Can be a Catalyst to Overcome these Challenges?
Chaos Engineering provides a structured approach to addressing these challenges and preventing unplanned downtime:
1. Identifying Vulnerabilities
By conducting controlled experiments, teams can pinpoint weaknesses in their systems. For example, by simulating a sudden surge in traffic, organizations can see how their applications respond and identify potential bottlenecks. This data-driven approach allows teams to take proactive measures before issues arise.
2. Improving System Resilience
According to a report, organizations that adopt chaos engineering practices see a 50% reduction in unplanned outages. By regularly testing their systems under various failure scenarios, teams can enhance their systems’ ability to withstand real-world issues, ultimately improving resilience.
3. Fostering a Culture of Experimentation
Implementing chaos engineering promotes a culture of continuous improvement. Teams become accustomed to testing their systems, leading to increased collaboration and knowledge sharing. This culture shift encourages innovation and can drive better performance across the organization.
4. Enhancing User Experience
When businesses prioritize resilience, they significantly reduce the risk of outages that negatively affect user experiences. A study from Google Cloud found that companies that implement chaos engineering report higher customer satisfaction and retention rates, directly impacting their revenue and brand loyalty.

The Bottom Line
In an era where downtime can lead to severe financial repercussions and lost customer trust, adopting Chaos Engineering practices is not just a luxury but a necessity. By identifying vulnerabilities, improving system resilience, fostering a culture of experimentation, and enhancing user experiences, businesses can proactively combat the threats posed by unplanned downtime. As organizations continue to navigate the complexities of modern digital environments, leveraging chaos engineering will become increasingly vital in ensuring consistent performance and customer satisfaction.
At Everforth Quinnox, we understand the high stakes of unplanned downtime and the critical role resilience plays in driving customer satisfaction and operational excellence. Our advanced digital solutions leverage Chaos Engineering principles, allowing us to identify vulnerabilities early, optimize system resilience, and maintain seamless user experiences.
Ready to turn Chaos Engineering into a core component of your digital transformation journey, ensuring not only stability but also a foundation for continuous innovation and growth?
Connect with our Experts Today!
To make observability truly effective, it’s not enough to collect data or even surface insights, you need a platform that can drive action. Qinfinite is designed to do exactly that, turning observability data into actionable insights and, most importantly, automating responses to keep your systems running smoothly.
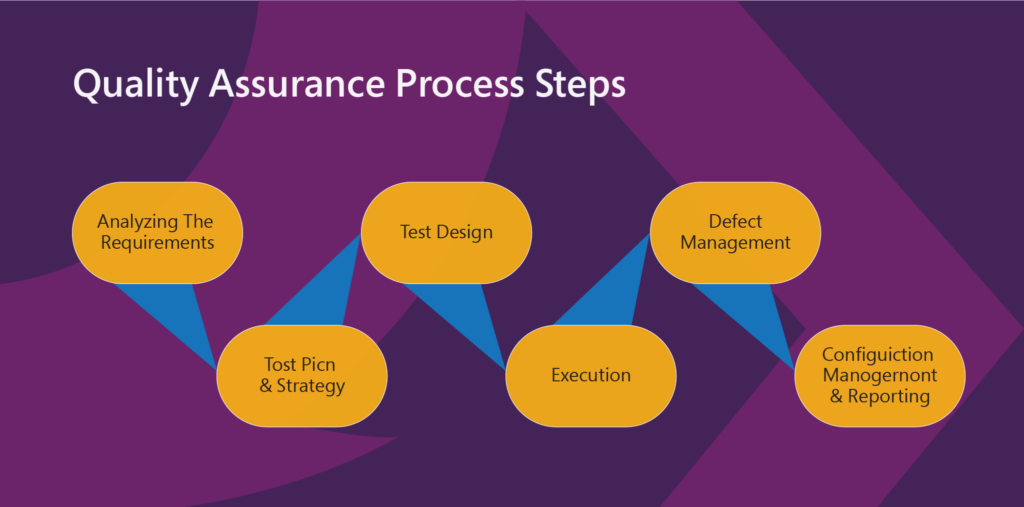
Initially, in the starting phase, the testing team is responsible for identifying the needs and determining the testing metrics by analyzing both functional and non-functional requirements. This step is essential for ensuring that all aspects of the software are covered during testing.
Develop a Requirement Traceability Matrix (RTM) to track requirements throughout the testing process. The RTM helps ensure that all requirements are tested and provides a clear link between requirements and test cases.
2. Test Planning:
Create a detailed test plan that outlines the project’s scope, timeline, resources, and costs. This plan serves as a roadmap for all testing activities and helps keep the team aligned on objectives.
Select appropriate testing tools based on project needs and team expertise. Factors such as ease of use, integration capabilities, and support should be considered when choosing tools.
Estimate efforts required for testing activities, including resource allocation and time management. Understanding these factors upfront can help prevent bottlenecks later in the process.
Identify any training needs for team members to ensure everyone is equipped with the necessary skills to execute their roles effectively.
3. User-Centric Testing:
4. Regular Training:
Invest in ongoing training for your QA team to keep them updated on best practices, tools, and technologies in software testing.
Encourage collaboration between different teams—development, operations, marketing—to ensure everyone is aligned on goals and understands how their work impacts overall quality.
Did you know? According to a report by Forrester, companies using cloud-based testing environments have reduced their testing costs by up to 45% while improving test coverage by 30%.
Implementing Modernization Strategies with Key Technologies
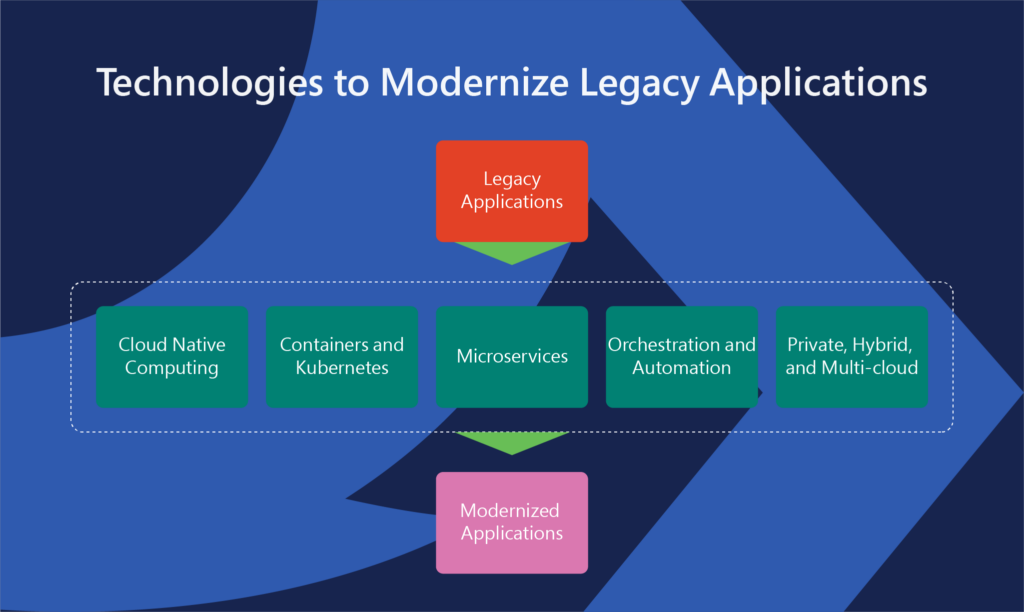
- Microservices: By breaking applications into silos, and creating deployable services, organizations can easily simplify updates, scaling, and maintenance. This modular approach allows teams to modify or enhance individual components without affecting the entire system.
- Containerization: Containers are responsible to create a consistent environment for applications throughout their lifecycle—starting from development to production. This feature is introduced the needed portability, scalability, and service isolation, making it easier to operate on applications easily across different platforms.
- Serverless Computing: Adopting serverless architectures enables businesses to minimize infrastructure management costs. This allows development teams to concentrate on writing code and implementing business logic rather than managing servers and infrastructure.
- Automation Tools: In automation when it comes to modernizing it starts by streamlining processes such as code analysis, dependency mapping, testing, and deployment. By reducing manual intervention, automation accelerates the modernization process and lowers the risk of errors.
Final Note
As organizations navigate the complexities of delivering high-quality products in a competitive market, QA testing serves as the bedrock of reliability and performance. By integrating best practices into every stage of the development lifecycle—from requirement analysis to test closure—businesses can ensure that their software not only meets but exceeds user expectations.
At Everforth Quinnox, we believe that QA is not just a process; it’s a systematic process focused on delivering exceptional user experiences with speed and efficiency. To match the current demand of modern software development, we offer our innovative AI-driven test automation platform Qyrus that helps organizations achieve:
- 213% ROI
- $1.03M NPV
- Payback in under 6 months
- 90% savings in QA and developer time